Introduction
Modern search systems increasingly aim to support natural language (NL) interfaces over structured or semi-structured indices. While large language models (LLMs) are capable of translating free-form text into structured queries, deploying such systems reliably over strict query languages—such as Apache Lucene query syntax—remains challenging.
Lucene’s query parser enforces precise syntactic rules. Even minor formatting mistakes (misplaced quotes, incorrect range expressions, missing operators) cause queries to fail outright. In practice, this makes naïve NL-to-query generation brittle and unsuitable for production systems.
This article describes a robust, production-oriented approach for translating natural language queries into syntactically valid Lucene queries by combining:
- documentation-grounded generation,
- deterministic parser validation, and
- an iterative correction loop that improves over time.
The focus is on engineering reliability, not prompt tricks.
Problem Statement
Converting natural language requests into valid Lucene queries presents several persistent challenges:
1. Syntactic Brittleness
LLMs frequently generate queries that are semantically close but syntactically invalid, causing hard parser failures and poor user experience.
2. Domain and Schema Ambiguity
Search indices often use domain-specific field names and query patterns. Generic NL-to-query approaches struggle without index-aware context.
3. Static Learning Approaches
Systems based solely on prompt engineering or periodic fine-tuning adapt slowly and require ongoing manual maintenance.
4. Lack of Explicit Validation
Many systems implicitly trust LLM output, despite Lucene syntax being deterministic and machine-verifiable.
These issues make it difficult to deploy dependable NL-based search interfaces on Lucene-backed systems such as Solr, OpenSearch, or Elasticsearch.
Design Principles
The system described here is guided by a few core principles:
- Deterministic systems should supervise probabilistic systems
- Validation must be explicit, not assumed
- Learning should come from successful executions
- Architecture should be model-agnostic
These principles strongly influence the system architecture.
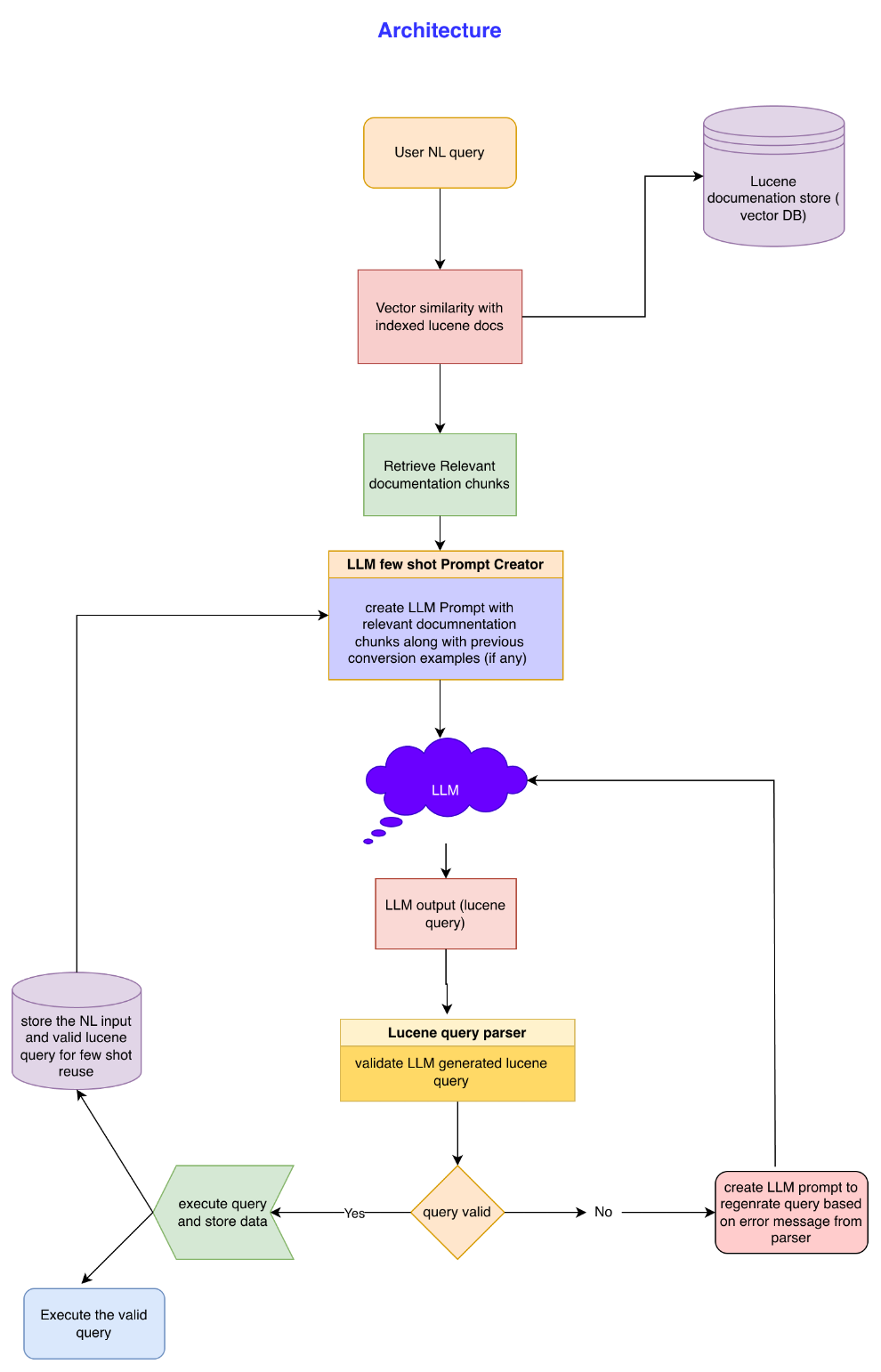
High-Level Architecture
At a high level, the system consists of four cooperating subsystems:
- Syntax Knowledge Index
- Contextual Retrieval Layer
- LLM-Based Query Generator
- Parser-Driven Validation and Feedback Loop
A persistent memory of successful translations enables gradual improvement.
Syntax Knowledge Index (Documentation Grounding)
Instead of relying on the LLM’s latent knowledge of Lucene syntax, the system explicitly grounds generation using official query syntax documentation.
Key steps:
- Lucene query documentation is segmented into logical sections (e.g., boolean queries, range queries, phrase queries).
- Each segment is converted into an embedding vector.
- The vectors are stored in a semantic index to support similarity-based retrieval.
This ensures the model operates with authoritative, context-specific syntax rules at generation time.
Contextual Query Retrieval
When a user submits a natural language query:
- The query is embedded.
- A semantic search retrieves the most relevant documentation snippets.
- These snippets form the context window for query generation.
This approach reduces hallucination and improves syntactic accuracy without requiring model fine-tuning.
LLM-Based Query Generation
The LLM is tasked with translating the natural language request into Lucene query syntax using:
- the original user query, and
- the retrieved documentation context.
The output is constrained to produce only the query expression, avoiding explanations or commentary.
At this stage, the output is considered tentative—not trusted.
Deterministic Validation via Lucene Parser
The generated query is passed directly to a standard Lucene query parser.
This parser acts as a ground-truth validator:
- If parsing succeeds, the query is accepted.
- If parsing fails, the exact error is captured.
This step is crucial: correctness is determined by the same component that will later execute the query.
Iterative Correction Loop
If a parsing error occurs:
- The original natural language query,
- the invalid generated query, and
- the parser’s error message
are fed back into the generation step.
The LLM is instructed to correct the previous attempt, explicitly accounting for the parser error.
This loop continues until:
- a valid query is produced, or
- a predefined retry limit is reached.
This design converts parser errors into actionable feedback, rather than terminal failures.
Experience-Based Learning (Few-Shot Memory)
Every successful translation is stored as a structured record containing:
- the original natural language query,
- intermediate failures (if any), and
- the final valid Lucene query.
Over time, this forms an experience memory.
For new queries:
- a similarity search retrieves relevant past examples,
- selected examples are included as few-shot guidance.
This enables the system to improve organically with usage, without retraining or prompt rewrites.
Core System Components
Conceptually, the system consists of:
-
Syntax Index (Static)
A semantic index of official Lucene syntax rules. -
Experience Index (Dynamic)
A growing collection of validated NL-to-query mappings. -
Query Orchestrator
Responsible for retrieval, prompt construction, retries, and persistence. -
Lucene Query Parser
The deterministic validator and final authority.
This separation keeps responsibilities clear and maintainable.
Advantages
-
Guaranteed Syntactic Validity
Queries are only accepted if they parse successfully. -
Adaptive Accuracy
The system improves automatically as more successful translations accumulate. -
Reduced Maintenance Overhead
No continuous fine-tuning or fragile prompt engineering. -
Efficient Context Usage
Only relevant syntax rules are provided to the model. -
Production-Friendly Error Handling
Failures are logged with full context for analysis and improvement.
Trade-offs and Limitations
-
Increased Latency
Iterative validation introduces additional round trips, mitigated by strict retry limits. -
System Complexity
Managing multiple indices and orchestration logic requires careful engineering. -
Cold Start Dependency
Initial effectiveness depends on the availability of quality documentation data.
These trade-offs are acceptable for systems where correctness outweighs raw throughput.
Closing Thoughts
Natural language interfaces over structured systems are only as reliable as their weakest failure mode. By treating deterministic parsers as supervisors rather than downstream consumers, it is possible to build LLM-powered systems that are both flexible and trustworthy.
The key lesson is simple:
Probabilistic models work best when constrained by deterministic truth.
This mindset is essential when bringing LLMs into production-grade search infrastructure.