Modern search systems increasingly rely on vector embeddings to find “similar” documents. This works remarkably well—until it doesn’t.
If you have ever tried to apply off-the-shelf embeddings to a highly domain-specific corpus, you may have noticed a recurring problem:
the results are linguistically reasonable but semantically wrong for your domain.
This post explores why off-the-shelf embeddings often fail in the “real world” and how to build domain-adaptive embeddings that actually understand your business logic.
The Hidden Assumption Behind Most Embeddings
Most popular embedding models are trained on massive, general-purpose text corpora. As a result, they learn a broad notion of similarity based on how words and sentences are used in everyday language.
This implicitly assumes that:
General language similarity is a good proxy for relevance in your application.
In many real-world systems, this assumption does not hold.
When “Similar” Doesn’t Mean “Relevant”
Consider a specialized domain such as:
- Legal documents
- Enterprise knowledge bases
- Technical or military texts
- Internal company documentation
In these contexts, similarity is defined by function or role, not by everyday language usage.
Imagine a Military or Aerospace search engine:
-
General Model: Sees “Wing” and “Bird” as highly similar (both are biological/flight-related).
-
Domain Reality: “Wing” is more related to “Flap” or “Fuselage.” A bird is just noise.
General-purpose embeddings are simply not trained to capture these nuances.
When your search engine sounds “smart” but retrieves the wrong technical documents, it’s not because the math is broken—it’s because the geometry of your embedding space doesn’t match your domain’s logic.
The Core Idea: Learn Similarity From the Domain Itself
Instead of asking a pre-trained model to guess what “similar” means in your domain, we can teach the system explicitly.
The idea is simple:
If you can provide examples of what should be considered similar (and dissimilar), you can train an embedding space that reflects your domain’s logic.
This shifts the problem from language modeling to similarity modeling.
A Practical Approach: Siamese Networks
One effective way to learn domain-specific similarity is using a Siamese neural network.
At a high level:
- The same neural network is applied to two inputs
- Each input is converted into a vector (an embedding) using the neural network
- Contrastive Loss: The training objective encourages:
- similar pairs to move closer together
- dissimilar pairs to move further apart
Over time, the model reshapes the embedding space so that distance reflects domain relevance, not general language usage.
You are no longer inheriting someone else’s definition of similarity—you are learning your own.
How to Implement This
Now let us see how to actually implement this architecutre.
Data preparation (The “Proximity” Trick)
To train our network, we need pairs of words and a similarity score (ranging from 0.0 to 1.0) that defines how closely they are related in your specific domain.
- The Goal: Create a dataset where {aws, s3} has a high score (1.0) while {aws, java} has a low score (0.3).
How to automate this: You don’t need to label thousands of pairs manually. You can extract these signals directly from your documents using word proximity:
-
Tokenize: Break your documents into sentences.
-
Calculate Distance: Words appearing close together in a sentence are likely related.
-
Labeling: Use the inverse distance between words as the similarity score.
The Logic: If two words frequently appear near each other in your technical manuals, they are likely related.
Example: In the phrase “OCI object storage”:
-
{oci, object} are neighbors → Score: 1.0
-
{oci, storage} are one word apart → Score: 0.5
-
{object, storage} are neighbors → Score: 1.0
This transforms your raw text into a map of domain-specific relationships.
Create neural network
While many use Python, high-performance enterprise systems often run on Java. Below is how we implement this architecture using Deep Java Library (DJL) with a PyTorch engine.
The Architecture
We define a simple feed-forward network to “reshape” the embeddings.
SequentialBlock().add(Linear.builder().setUnits(32).build())
.add(Activation::relu)
.add(Linear.builder().setUnits(embedDim).build());
Train the network
Here we encode and pass both word pairs of the dataset through the same network
e1 = trainer.forward(new NDList(word1)).singletonOrThrow();
e2 = trainer.forward(new NDList(word1)).singletonOrThrow();
This is where the magic happens. We calculate the distance between our “twins” and apply the loss.
loss = y × dist² + (1-y) × max(margin - dist, 0)²
dist - euclidean distance between e1 and e2 margin - The minimum distance we want between dissimilar pairs. It’s a hyperparameter that defines “how far is far enough” for words that shouldn’t be similar. This can be configured as per our use case.
-
If y=1 (Similar): The loss increases if the distance is high. The model pulls them together.
-
If y=0 (Dissimilar): The loss increases if they are too close. The model pushes them apart until they hit a “margin” of safety.
This process can be repeated for N no of epochs.
Embedding new documents
Once we have trained our neural network, we can use it for vectorizing new documents. The document can be tokenized into words and each word can be passed through our trained network to create the vectors
NDArray e1 = predictor.predict(new NDList(x1)).singletonOrThrow(); // (1, embedDim)
These vectors can then be stored in a vector database.
Evaluating the Results: Domain Awareness
To truly understand the value of a custom embedding, we need to look at how it perceives relationships that are “obvious” to a human expert but ambiguous to a general-purpose model.
Consider the relationship between “aws” and “s3”. In a cloud computing context, these are inseparable. However, a generic model trained on a massive, diverse dataset might only see a loose connection because “s3” could also refer to a specific car model, a type of document, or an algebraic group.
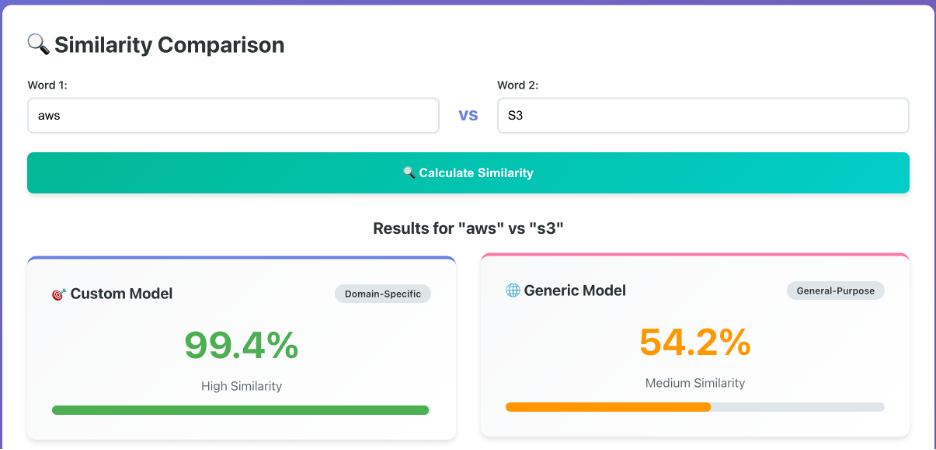
Key Observations:
-
The Generic Gap: The generic model returns a similarity of 54.2%. In a RAG (Retrieval-Augmented Generation) pipeline, this “medium similarity” often isn’t enough to trigger a high-ranking retrieval, causing the system to miss relevant documentation.
-
The Custom Precision: After training on domain-specific data, the custom model jumps to 99.4%. It has learned that in this specific universe, “s3” almost always implies “aws.”
-
Impact on Retrieval: This 45% gain isn’t just a number—it represents the difference between an AI that gives a vague “I don’t know” and one that finds the exact configuration steps for an S3 bucket instantly.
Why This Matters for Search Systems
Once trained, these embeddings can be used exactly like any other vector representation.
- Stored in a vector database
- Indexed using ANN algorithms
- Queried using cosine similarity or distance metrics
The difference is not in the retrieval infrastructure, but in the geometry of the embedding space itself.
In practice, this often leads to:
-
Contextual Precision: Your search engine finally understands that in your company, “Pipeline” refers to a CI/CD process, not a literal oil pipe.
-
Reduced Hallucinations: In RAG systems, if the retrieval step is garbage, the LLM output will be garbage. Better embeddings = better context = better answers.
-
Embeddings as Code: You are now treating your embedding space as a design choice, encoding business logic directly into the math of your system.
A Key Insight: Embeddings Are a Design Choice
Embeddings are often treated as a black box: pick a model, generate vectors, and move on.
In reality, embeddings are a core design decision.
By training embeddings on domain-specific similarity signals, you are effectively encoding business logic, domain expertise, and relevance criteria directly into the representation layer of your system.
This is especially valuable in:
- Enterprise search
- Regulated industries
- Internal tooling
- High-precision retrieval use cases
Trade-offs and Practical Considerations
This approach is not a silver bullet.
It requires:
- Curated similarity signals (even a small set helps)
- Careful thinking about what “similar” really means
- Periodic retraining as the domain evolves
However, it offers something generic embeddings cannot:
control.
You decide what the system should consider similar—and the model learns accordingly.
For regulated industries (Legal, MedTech) or complex Enterprise SaaS, this is the difference between a “toy” AI and a production-ready tool.
Why This Matters for Real-World Engineering Teams
From an engineering perspective, this approach demonstrates:
- An understanding of the limits of pre-trained models
- The ability to adapt ML techniques to domain constraints
- A system-level view of search and retrieval, not just model usage
These are exactly the kinds of trade-offs encountered in production systems, especially in enterprise and platform teams across Europe.
Closing Thoughts
Generic embeddings are powerful—but they are not neutral. They don’t know your business, your acronyms, or your workflows. They encode assumptions that may not match your domain.
By building domain-adaptive embeddings, you stop relying on someone else’s definition of similarity and start building a system that actually understands what matters to your users.
When similarity matters, learning your own embedding space can be the difference between a system that merely looks intelligent and one that actually understands what matters.
I have implemented a simple version of this in the below github repo. check it out if you are interested:
🐙 GitHub Repository:
https://github.com/navaneethpt/custom-embedding-app